

本套课程来自小象学院:《自然语言处理》第二期,课程官方售价699元,由秦曾昌老师主讲,共22个章节, 包含课程视频与源码资料。语言是人类区别其他动物的本质特性,只有人类能够用语言表达自己的想法。用自然语言与计算机进行通信,这是人们长期以来所追求的,那如何才能将它们联系起来呢?自然语言如何进行处理呢?学习本套课程你将收获到语言模型、语言技术、神经语言模型、循环神经网络、机器翻译等,更多技能需要自己通过学习才能解锁喔,文章底部附下载地址。
如果对人工智能和AI比较感兴趣的同学,也可以学习一下秦曾昌老师的另外一套课程机器学习算法精讲,该课程旨在解决大家算法能力薄弱的问题。

《自然语言处理》第二期 视频截图
《自然语言处理》第二期 视频截图
课程文件目录:V-1992:《自然语言处理》第二期[2.3G]
01-第1章:自然语言与数学之美
1.1 课程简介及推荐书目
1.10 凸集合和凸函数
1.2 NLP的研究领域及应用
1.3 自然语言的6个重要术语
1.4 语言学的发展史 1
1.5 语言学的发展史 2
1.6 语言学的发展史 3
1.7 函数
1.8 向量与向量的模
1.9 矩阵和矩阵运算
02-第2章:基于机器学习方法的自然语言处理
2.1 主观概率和客观概率
2.10 辛普森悖论和贝叶斯概率解题实例
2.2 概率模型与条件概率
2.3 贝叶斯原理与推理
2.4 随机变量:二项式概率
2.5 随机变量:期望与方差
2.6 随机变量:联合概率
2.7 伯努利分布和二项式分布
2.8 多项式分布、伽玛分布和Beta分布
2.9 泊松分布、高斯分布、对数正态分布和指数分布
03-第3章:1、2章答疑
第一周答疑
04-第4章:自然语言
3.1 语言的进化:来自自然选择的社会协作
3.2 语言的进化:语言游戏与摩斯密码
3.3 语言与智能:信息熵
3.4 语言与智能:交叉熵的定义
3.5 语义的进化
3.6 语言模型:语言概率
3.7 词袋模型
3.8 二元语言模型:CR情感分析
05-第5章:语言模型和中文分词
4.1 三元语言模型
4.10 N-Gram模型
4.11 Optimal Path 最优路径模型
4.12 中文分词工具:Jieba
4.2 语言模型评价:交叉熵
4.3 语言模型评价:Perplexity(困惑度)
4.4 语言评价模型:Interpolation(插值法)
4.5 概率模型:垃圾邮件分类
4.6 概率模型:拼写检查
4.7 语音模型和机器翻译模型
4.8 中文构词法
4.9 最大化匹配
06-第6章:第二周答疑
第二周答疑
07-第7章:语言技术-词表达和Word2Vec
5.1 词表达
5.10 Word2Vec-Part 3
5.2 语义相似度
5.3 TF-IDF权重处理
5.4 One-Hot表达
5.5 神经网络基础
5.6 神经网络:反向传播 1
5.7 神经网络:反向传播 2
5.8 Word2Vec-Part 1
5.9 Word2Vec-Part 2
08-第8章:语言技术-词性
6.1 什么是词性标注(POS Tagging)
6.10 混合模型详解5:隐马尔科夫模型
6.2 词性标注的方法
6.3 词性的标注类别和标注集
6.4 规则标注和N-Gram方法
6.5 从混合模型到HMM
6.6 混合模型详解1:EM模型
6.7 混合模型详解2:EM模型
6.8 混合模型详解3:高斯混合模型
6.9 混合模型详解4:隐马尔可夫模型
09-第9章:第三周答疑
第三周答疑
10-第10章:语言技术-概率图模型
7.1 概率图模型:贝叶斯网络(有向无环图)
7.2 概率图模型:分层图模型
7.3 概率图模型:隐马尔科夫链
7.4 隐马尔可夫模型的推导 1
7.5 隐马尔科夫模型的推导 2
7.6 隐马尔科夫模型的推导 3
7.7 隐马尔科夫模型的推导 4
7.8 PLSA主题模型1
7.9 PLSA主题模型 2
11-第11章:语言技术-文本与LDA主题模型
8.1 向量表达和潜在语义索引(LSI)
8.10 实验报告:文本语义相似度
8.11 延展实验:主题模型引入字词关系的实现
8.12 实验总结
8.2 LDA和狄利克雷分布
8.3 LDA主题模型
8.4 主题模型的深化与对比
8.5 语义距离(Semantic Distance)
8.6 中文LDA模型:Word-base 和 Character-Base
8.7 实验报告:困惑度(Perplexity)
8.8 实验报告:文本分类准确度
8.9 中英双语料库实验
12-第12章:第四周答疑
第四周答疑
13-第13章:语言技术-句法
9.1 上下文无关句法(CFG)-Part 1
9.2 上下文无关句法(CFG)-Part 2
9.3 概率上下文无关句法(PCFG)- Part 1
9.4 概率上下文无关句法(PCFG)-Part 2
9.5 概率上下文无关句法(PCGF)-Part 3
14-第14章:机器翻译
10.1 机器翻译(Machine Translation)-Part 1
10.2 机器翻译(Machine Translation)-Part 2
10.3 机器翻译(Machine Translation)-Part 3
10.4 机器翻译(Machine Translation)-Part 4
10.5 机器翻译(Machine Translation)-Part 5
10.6 机器翻译(Machine Translation)-Part 6
15-第15章:第五周答疑
第五周答疑
16-第16章:卷积神经网络CNN
11.1 神经元
11.2 全连接网络及特性
11.3 Auto-Encode 自编码器
11.4 反向传播(BP)
11.5 卷积神经网络(CNN)的理解
11.6 CNN的基本原理:卷积核、权重和池化
11.7 CNN的计算过程
11.8 CNN如何应用在自然语言处理中
17-第17章:循环神经网络RNN
12.1 循环神经网络的基本原理
12.2 Elman Network和Jordan Networ
12.3 LSTM的核心思想
12.4 LSTM的分步实现详解
12.5 Encoder-Decoder 框架
12.6 Seq2Seq 模型
12.7 注意力机制(Attention Mechanism)
18-第18章:第六周答疑
第六周答疑
19-第19章:注意力机制
13.1 注意力机制产生的背景回顾
13.2 注意力模型的实现原理
13.3 注意力模型的应用领域
13.4 记忆网络(Memory Network)的组成
13.5 记忆网络的计算过程和实现方法
13.6 匹配函数(Match Function)
13.7 注意力模型的延展1:Neural Programmer
13.8 注意力模型的延展2:神经图灵机
20-第20章:广义模型(Universal Transformer)
14.1 UT的典型结构:Stack of Encoder and Decoder
14.2 Self-Attention的计算
14.3 Multi-Head Attention 和前向反馈神经网络FFNN
14.4 位置编码(Positional Encoding)
14.5 层泛化(Lay Normalization)
14.6 Softmax Layer:交叉熵和损失函数的计算
14.7 ACT模型(Adaptive Computation Time)
14.8 Universal Transformer 的完整实现流程
21-第21章:第七周答疑
第七周答疑
22-第22章:自然语言研究的未来方向
15.1 自然语言研究可行方向:知识图谱与深度学习的结合
15.2 语义关系计算与知识库
15.3 知识库推理学习:Neural Tensor Network
15.4 跨媒体信息搜索:CMIR
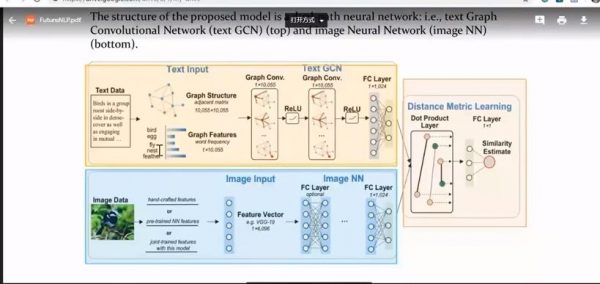
15.5 文本图卷积网络(Text GCN)
15.6 NLP未来的探索方向
资料







